Resampling Techniques, Bootstrap and Blocking#
Why resampling methods ?#
Statistical analysis.
* Our simulations can be treated as *computer experiments*. This is particularly the case for Monte Carlo methods
* The results can be analysed with the same statistical tools as we would use analysing experimental data.
* As in all experiments, we are looking for expectation values and an estimate of how accurate they are, i.e., possible sources for errors.
Statistical analysis#
* As in other experiments, many numerical experiments have two classes of errors:
* Statistical errors
* Systematical errors
* Statistical errors can be estimated using standard tools from statistics
* Systematical errors are method specific and must be treated differently from case to case.
Statistics, wrapping up from last week#
Let us analyze the problem by splitting up the correlation term into partial sums of the form:
The correlation term of the error can now be rewritten in terms of \(f_d\)
The value of \(f_d\) reflects the correlation between measurements separated by the distance \(d\) in the sample samples. Notice that for \(d=0\), \(f\) is just the sample variance, \(\mathrm{var}(x)\). If we divide \(f_d\) by \(\mathrm{var}(x)\), we arrive at the so called autocorrelation function
which gives us a useful measure of pairwise correlations starting always at \(1\) for \(d=0\).
Statistics, final expression#
The sample error can now be written in terms of the autocorrelation function:
and we see that \(\mathrm{err}_X\) can be expressed in terms the uncorrelated sample variance times a correction factor \(\tau\) which accounts for the correlation between measurements. We call this correction factor the autocorrelation time:
Statistics, effective number of correlations#
For a correlation free experiment, \(\tau\) equals 1.
We can interpret a sequential correlation as an effective reduction of the number of measurements by a factor \(\tau\). The effective number of measurements becomes:
To neglect the autocorrelation time \(\tau\) will always cause our simple uncorrelated estimate of \(\mathrm{err}_X^2\approx \mathrm{var}(x)/n\) to be less than the true sample error. The estimate of the error will be too good. On the other hand, the calculation of the full autocorrelation time poses an efficiency problem if the set of measurements is very large.
Can we understand this? Time Auto-correlation Function#
The so-called time-displacement autocorrelation \(\phi(t)\) for a quantity \(\mathbf{M}\) is given by
which can be rewritten as
where \(\langle \mathbf{M} \rangle\) is the average value and \(\mathbf{M}(t)\) its instantaneous value. We can discretize this function as follows, where we used our set of computed values \(\mathbf{M}(t)\) for a set of discretized times (our Monte Carlo cycles corresponding to moving all electrons?)
Time Auto-correlation Function#
One should be careful with times close to \(t_{\mathrm{max}}\), the upper limit of the sums becomes small and we end up integrating over a rather small time interval. This means that the statistical error in \(\phi(t)\) due to the random nature of the fluctuations in \(\mathbf{M}(t)\) can become large.
One should therefore choose \(t \ll t_{\mathrm{max}}\).
Note that the variable \(\mathbf{M}\) can be any expectation values of interest.
The time-correlation function gives a measure of the correlation between the various values of the variable at a time \(t'\) and a time \(t'+t\). If we multiply the values of \(\mathbf{M}\) at these two different times, we will get a positive contribution if they are fluctuating in the same direction, or a negative value if they fluctuate in the opposite direction. If we then integrate over time, or use the discretized version of, the time correlation function \(\phi(t)\) should take a non-zero value if the fluctuations are correlated, else it should gradually go to zero. For times a long way apart the different values of \(\mathbf{M}\) are most likely uncorrelated and \(\phi(t)\) should be zero.
Time Auto-correlation Function#
We can derive the correlation time by observing that our Metropolis algorithm is based on a random walk in the space of all possible spin configurations. Our probability distribution function \(\mathbf{\hat{w}}(t)\) after a given number of time steps \(t\) could be written as
with \(\mathbf{\hat{w}}(0)\) the distribution at \(t=0\) and \(\mathbf{\hat{W}}\) representing the transition probability matrix. We can always expand \(\mathbf{\hat{w}}(0)\) in terms of the right eigenvectors of \(\mathbf{\hat{v}}\) of \(\mathbf{\hat{W}}\) as
resulting in
with \(\lambda_i\) the \(i^{\mathrm{th}}\) eigenvalue corresponding to
the eigenvector \(\mathbf{\hat{v}}_i\).
Time Auto-correlation Function#
If we assume that \(\lambda_0\) is the largest eigenvector we see that in the limit \(t\rightarrow \infty\), \(\mathbf{\hat{w}}(t)\) becomes proportional to the corresponding eigenvector \(\mathbf{\hat{v}}_0\). This is our steady state or final distribution.
We can relate this property to an observable like the mean energy. With the probabilty \(\mathbf{\hat{w}}(t)\) (which in our case is the squared trial wave function) we can write the expectation values as
or as the scalar of a vector product
with \(\mathbf{m}\) being the vector whose elements are the values of \(\mathbf{M}_{\mu}\) in its various microstates \(\mu\).
Time Auto-correlation Function#
We rewrite this relation as
If we define \(m_i=\mathbf{\hat{v}}_i\mathbf{m}_i\) as the expectation value of \(\mathbf{M}\) in the \(i^{\mathrm{th}}\) eigenstate we can rewrite the last equation as
Since we have that in the limit \(t\rightarrow \infty\) the mean value is dominated by the the largest eigenvalue \(\lambda_0\), we can rewrite the last equation as
We define the quantity
and rewrite the last expectation value as
Time Auto-correlation Function#
The quantities \(\tau_i\) are the correlation times for the system. They control also the auto-correlation function discussed above. The longest correlation time is obviously given by the second largest eigenvalue \(\tau_1\), which normally defines the correlation time discussed above. For large times, this is the only correlation time that survives. If higher eigenvalues of the transition matrix are well separated from \(\lambda_1\) and we simulate long enough, \(\tau_1\) may well define the correlation time. In other cases we may not be able to extract a reliable result for \(\tau_1\). Coming back to the time correlation function \(\phi(t)\) we can present a more general definition in terms of the mean magnetizations \( \langle \mathbf{M}(t) \rangle\). Recalling that the mean value is equal to \( \langle \mathbf{M}(\infty) \rangle\) we arrive at the expectation values
resulting in
which is appropriate for all times.
Correlation Time#
If the correlation function decays exponentially
then the exponential correlation time can be computed as the average
If the decay is exponential, then
which suggests another measure of correlation
called the integrated correlation time.
Resampling methods: Jackknife and Bootstrap#
Two famous resampling methods are the independent bootstrap and the jackknife.
The jackknife is a special case of the independent bootstrap. Still, the jackknife was made popular prior to the independent bootstrap. And as the popularity of the independent bootstrap soared, new variants, such as the dependent bootstrap.
The Jackknife and independent bootstrap work for independent, identically distributed random variables. If these conditions are not satisfied, the methods will fail. Yet, it should be said that if the data are independent, identically distributed, and we only want to estimate the variance of \(\overline{X}\) (which often is the case), then there is no need for bootstrapping.
Resampling methods: Jackknife#
The Jackknife works by making many replicas of the estimator \(\widehat{\theta}\). The jackknife is a resampling method, we explained that this happens by scrambling the data in some way. When using the jackknife, this is done by systematically leaving out one observation from the vector of observed values \(\hat{x} = (x_1,x_2,\cdots,X_n)\). Let \(\hat{x}_i\) denote the vector
which equals the vector \(\hat{x}\) with the exception that observation number \(i\) is left out. Using this notation, define \(\widehat{\theta}_i\) to be the estimator \(\widehat{\theta}\) computed using \(\vec{X}_i\).
Resampling methods: Jackknife estimator#
To get an estimate for the bias and standard error of \(\widehat{\theta}\), use the following estimators for each component of \(\widehat{\theta}\)
Jackknife code example#
from numpy import *
from numpy.random import randint, randn
from time import time
def jackknife(data, stat):
n = len(data);t = zeros(n); inds = arange(n); t0 = time()
## 'jackknifing' by leaving out an observation for each i
for i in range(n):
t[i] = stat(delete(data,i) )
# analysis
print("Runtime: %g sec" % (time()-t0)); print("Jackknife Statistics :")
print("original bias std. error")
print("%8g %14g %15g" % (stat(data),(n-1)*mean(t)/n, (n*var(t))**.5))
return t
# Returns mean of data samples
def stat(data):
return mean(data)
mu, sigma = 100, 15
datapoints = 10000
x = mu + sigma*random.randn(datapoints)
# jackknife returns the data sample
t = jackknife(x, stat)
Runtime: 0.138923 sec
Jackknife Statistics :
original bias std. error
100.123 100.113 0.150177
Resampling methods: Bootstrap#
Bootstrapping is a nonparametric approach to statistical inference that substitutes computation for more traditional distributional assumptions and asymptotic results. Bootstrapping offers a number of advantages:
The bootstrap is quite general, although there are some cases in which it fails.
Because it does not require distributional assumptions (such as normally distributed errors), the bootstrap can provide more accurate inferences when the data are not well behaved or when the sample size is small.
It is possible to apply the bootstrap to statistics with sampling distributions that are difficult to derive, even asymptotically.
It is relatively simple to apply the bootstrap to complex data-collection plans (such as stratified and clustered samples).
Resampling methods: Bootstrap background#
Since \(\widehat{\theta} = \widehat{\theta}(\hat{X})\) is a function of random variables, \(\widehat{\theta}\) itself must be a random variable. Thus it has a pdf, call this function \(p(\hat{t})\). The aim of the bootstrap is to estimate \(p(\hat{t})\) by the relative frequency of \(\widehat{\theta}\). You can think of this as using a histogram in the place of \(p(\hat{t})\). If the relative frequency closely resembles \(p(\vec{t})\), then using numerics, it is straight forward to estimate all the interesting parameters of \(p(\hat{t})\) using point estimators.
Resampling methods: More Bootstrap background#
In the case that \(\widehat{\theta}\) has more than one component, and the components are independent, we use the same estimator on each component separately. If the probability density function of \(X_i\), \(p(x)\), had been known, then it would have been straight forward to do this by:
Drawing lots of numbers from \(p(x)\), suppose we call one such set of numbers \((X_1^*, X_2^*, \cdots, X_n^*)\).
Then using these numbers, we could compute a replica of \(\widehat{\theta}\) called \(\widehat{\theta}^*\).
By repeated use of (1) and (2), many estimates of \(\widehat{\theta}\) could have been obtained. The idea is to use the relative frequency of \(\widehat{\theta}^*\) (think of a histogram) as an estimate of \(p(\hat{t})\).
Resampling methods: Bootstrap approach#
But unless there is enough information available about the process that generated \(X_1,X_2,\cdots,X_n\), \(p(x)\) is in general unknown. Therefore, Efron in 1979 asked the question: What if we replace \(p(x)\) by the relative frequency of the observation \(X_i\); if we draw observations in accordance with the relative frequency of the observations, will we obtain the same result in some asymptotic sense? The answer is yes.
Instead of generating the histogram for the relative frequency of the observation \(X_i\), just draw the values \((X_1^*,X_2^*,\cdots,X_n^*)\) with replacement from the vector \(\hat{X}\).
Resampling methods: Bootstrap steps#
The independent bootstrap works like this:
Draw with replacement \(n\) numbers for the observed variables \(\hat{x} = (x_1,x_2,\cdots,x_n)\).
Define a vector \(\hat{x}^*\) containing the values which were drawn from \(\hat{x}\).
Using the vector \(\hat{x}^*\) compute \(\widehat{\theta}^*\) by evaluating \(\widehat \theta\) under the observations \(\hat{x}^*\).
Repeat this process \(k\) times.
When you are done, you can draw a histogram of the relative frequency of \(\widehat \theta^*\). This is your estimate of the probability distribution \(p(t)\). Using this probability distribution you can estimate any statistics thereof. In principle you never draw the histogram of the relative frequency of \(\widehat{\theta}^*\). Instead you use the estimators corresponding to the statistic of interest. For example, if you are interested in estimating the variance of \(\widehat \theta\), apply the etsimator \(\widehat \sigma^2\) to the values \(\widehat \theta ^*\).
Code example for the Bootstrap method#
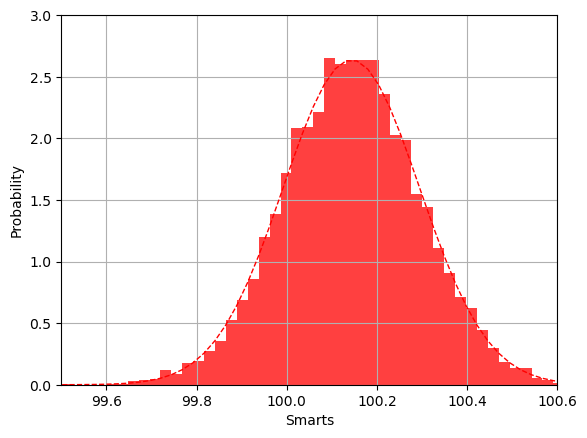
The following code starts with a Gaussian distribution with mean value \(\mu =100\) and variance \(\sigma=15\). We use this to generate the data used in the bootstrap analysis. The bootstrap analysis returns a data set after a given number of bootstrap operations (as many as we have data points). This data set consists of estimated mean values for each bootstrap operation. The histogram generated by the bootstrap method shows that the distribution for these mean values is also a Gaussian, centered around the mean value \(\mu=100\) but with standard deviation \(\sigma/\sqrt{n}\), where \(n\) is the number of bootstrap samples (in this case the same as the number of original data points). The value of the standard deviation is what we expect from the central limit theorem.
%matplotlib inline
%matplotlib inline
from numpy import *
from numpy.random import randint, randn
from time import time
from scipy.stats import norm
import matplotlib.pyplot as plt
# Returns mean of bootstrap samples
def stat(data):
return mean(data)
# Bootstrap algorithm
def bootstrap(data, statistic, R):
t = zeros(R); n = len(data); inds = arange(n); t0 = time()
# non-parametric bootstrap
for i in range(R):
t[i] = statistic(data[randint(0,n,n)])
# analysis
print("Runtime: %g sec" % (time()-t0)); print("Bootstrap Statistics :")
print("original bias std. error")
print("%8g %8g %14g %15g" % (statistic(data), std(data),\
mean(t), \
std(t)))
return t
mu, sigma = 100, 15
datapoints = 10000
x = mu + sigma*random.randn(datapoints)
# bootstrap returns the data sample t = bootstrap(x, stat, datapoints)
# the histogram of the bootstrapped data
t = bootstrap(x, stat, datapoints)
# the histogram of the bootstrapped data
n, binsboot, patches = plt.hist(t, bins=50, density='true',histtype='bar', color='red', alpha=0.75)
# add a 'best fit' line
y = norm.pdf( binsboot, mean(t), std(t))
lt = plt.plot(binsboot, y, 'r--', linewidth=1)
plt.xlabel('Smarts')
plt.ylabel('Probability')
plt.axis([99.5, 100.6, 0, 3.0])
plt.grid(True)
plt.show()
Runtime: 1.23226 sec
Bootstrap Statistics :
original bias std. error
100.143 15.1234 100.143 0.151293
Resampling methods: Blocking#
The blocking method was made popular by Flyvbjerg and Pedersen (1989) and has become one of the standard ways to estimate \(V(\widehat{\theta})\) for exactly one \(\widehat{\theta}\), namely \(\widehat{\theta} = \overline{X}\).
Assume \(n = 2^d\) for some integer \(d>1\) and \(X_1,X_2,\cdots, X_n\) is a stationary time series to begin with. Moreover, assume that the time series is asymptotically uncorrelated. We switch to vector notation by arranging \(X_1,X_2,\cdots,X_n\) in an \(n\)-tuple. Define:
The strength of the blocking method is when the number of observations, \(n\) is large. For large \(n\), the complexity of dependent bootstrapping scales poorly, but the blocking method does not, moreover, it becomes more accurate the larger \(n\) is.
Blocking Transformations#
We now define blocking transformations. The idea is to take the mean of subsequent pair of elements from \(\vec{X}\) and form a new vector \(\vec{X}_1\). Continuing in the same way by taking the mean of subsequent pairs of elements of \(\vec{X}_1\) we obtain \(\vec{X}_2\), and so on. Define \(\vec{X}_i\) recursively by:
The quantity \(\vec{X}_k\) is subject to \(k\) blocking transformations. We now have \(d\) vectors \(\vec{X}_0, \vec{X}_1,\cdots,\vec X_{d-1}\) containing the subsequent averages of observations. It turns out that if the components of \(\vec{X}\) is a stationary time series, then the components of \(\vec{X}_i\) is a stationary time series for all \(0 \leq i \leq d-1\)
We can then compute the autocovariance, the variance, sample mean, and number of observations for each \(i\). Let \(\gamma_i, \sigma_i^2, \overline{X}_i\) denote the autocovariance, variance and average of the elements of \(\vec{X}_i\) and let \(n_i\) be the number of elements of \(\vec{X}_i\). It follows by induction that \(n_i = n/2^i\).
Blocking Transformations#
Using the definition of the blocking transformation and the distributive property of the covariance, it is clear that since \(h =|i-j|\) we can define
The quantity \(\hat{X}\) is asymptotic uncorrelated by assumption, \(\hat{X}_k\) is also asymptotic uncorrelated. Let’s turn our attention to the variance of the sample mean \(V(\overline{X})\).
Blocking Transformations, getting there#
We have
The term \(e_k\) is called the truncation error:
We can show that \(V(\overline{X}_i) = V(\overline{X}_j)\) for all \(0 \leq i \leq d-1\) and \(0 \leq j \leq d-1\).
Blocking Transformations, final expressions#
We can then wrap up
By repeated use of this equation we get \(V(\overline{X}_i) = V(\overline{X}_0) = V(\overline{X})\) for all \(0 \leq i \leq d-1\). This has the consequence that
Flyvbjerg and Petersen demonstrated that the sequence \(\{e_k\}_{k=0}^{d-1}\) is decreasing, and conjecture that the term \(e_k\) can be made as small as we would like by making \(k\) (and hence \(d\)) sufficiently large. The sequence is decreasing (Master of Science thesis by Marius Jonsson, UiO 2018). It means we can apply blocking transformations until \(e_k\) is sufficiently small, and then estimate \(V(\overline{X})\) by \(\widehat{\sigma}^2_k/n_k\).
For an elegant solution and proof of the blocking method, see the recent article of Marius Jonsson (former MSc student of the Computational Physics group).